
나홀로 데이터 분석가의 1인 연구실
[웹 크롤링] HTML이란? 본문
0-1. HTML이란?
웹 크롤링을 하기 앞서 기본적인 개념을 이해할 필요가 있습니다.
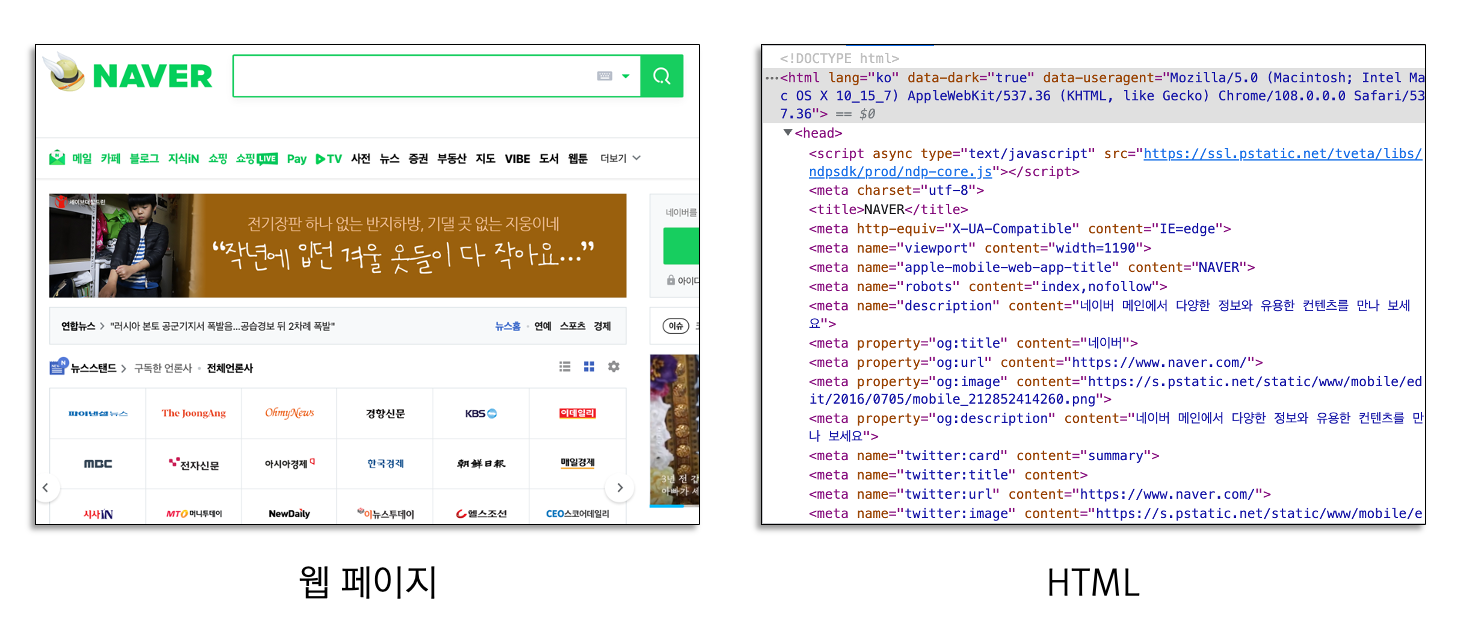
<그림 1>에서 웹 페이지는 우리가 평소 웹 브라우저에 접속하면 보이는 화면입니다.
이러한 페이지를 구성하는 것은 <그림 1>의 우측인 HTML 구조로 되어있습니다.
웹 크롤링은 이 HTML 구조에서 정보를 뽑아오는 것입니다.
0-2. HTML의 계층구조
HTML 구조는 기본적으로 계층구조로 되어 있습니다.
계층구조는 간단히 생각하면 컴퓨터의 폴더 구조와 비슷하다고 보시면 됩니다.
ex. [바탕화면] > [대학원] 폴더 > [1학기] 폴더 > [3월] 폴더 > [레포트.txt]
웹 크롤링은 이러한 폴더 안에 있는 파일을 검색을 통해 찾아오는 것입니다.

HTML의 계층구조에 대해 감을 잡으셨다면, 이제 가상으로 크롤링을 해볼 것입니다.
만약 제가 5월에 쓴 성적이라는 파일을 가져오기 위해서는 어떻게 해야 할까요?
아래와 같이 다양한 방법이 있을 것입니다.
- 경로를 그대로 검색하여 찾아오는 방법: [대학원] > [1학기] > [5월] > [성적.txt]
- [1학기] 안에 있는 파일을 모두 불러온 후, [성적.txt] 라는 파일만 추출하는 방법: [1학기] > [성적.txt]
- [대학원] 안에 [성적.txt]를 모두 불러온 후, 5월에 해당하는 파일을 걸러내는 방법: [대학원] > [성적.txt]
제 경험상 크롤링을 비롯하여 코딩을 할 때, 딱 1가지 방법만 있는 경우는 드물다고 생각합니다.
다만, 더 효율적인 방법을 찾을 수 있느냐가 코딩을 잘한다는 기준인 것 같습니다.
'Python > Theory' 카테고리의 다른 글
| [시각화] plt.scatter()를 활용한 산점도 그리기 (0) | 2023.01.02 |
|---|---|
| [Python] 데이터 전처리를 위한 apply(lambda)문 사용하기 (0) | 2022.12.28 |
| [Python] tqdm을 통해 for, apply문 진행율 확인하기 (0) | 2022.12.27 |
| [Python] 라이브러리 설치 시 [WinError 5] 에러 대처하기 (0) | 2022.12.27 |
| [웹 크롤링] find_all 함수로 웹 페이지 내 Element 추출하기 (0) | 2022.12.26 |
'Python/Theory' Related Articles
more


Comments